
Microsoft Certified: Azure Data Engineer Associate “DP-203”. DP-203 is the latest exam question released in 2021. I have gone through the DP-200 exam and DP-201 exam before.
From August 31, 2021, the exams DP-200 and DP-201 have been discontinued, and all those who need to participate in the “Implementing an Azure Data Solution” have been changed to participate in the “Data Engineering on Microsoft Azure”.
The DP-203 exam is a new advancement, and each update iteration of Microsoft is a very big advancement. Of course, such advancement also increases the difficulty of the exam for examinees.
Based on the above description, my explanation is that Microsoft has simplified the previous exam steps and increased the difficulty of the exam. Regardless of whether you want to pass the exam before or now, the most important thing is to study hard, participate in the community, and practice exams to improve your skills.
Today I will share 15 newly updated Microsoft DP-203 exam questions to help you learn the test online. There is no way for free exam questions to help you really pass the exam.
You can enter leads4pass DP-203 dumps: https://www.leads4pass.com/dp-203.html (Total Questions: 214 Q&A). leads4pass has a pass rate of more than 99%, Years of exam experience, an excellent team of exam experts, and a perfect exam policy. leads4pass is our free content provider.
Microsoft DP-203 historical exam dumps collection online sharing
https://www.fulldumps.com/why-not-try-lead4pass-dp-203-exam-dumps-100-pass-exam/
Please take the latest updated Microsoft DP-203 exam test
Verify the answer at the end of the article
Question 1:
What should you recommend using to secure sensitive customer contact information?
A. Transparent Data Encryption (TDE)
B. row-level security
C. column-level security
D. data sensitivity labels
Scenario: Limit the business analysts
Question 2:
What should you do to improve high availability of the real-time data processing solution?
A. Deploy a High Concurrency Databricks cluster.
B. Deploy an Azure Stream Analytics job and use an Azure Automation runbook to check the status of the job and to start the job if it stops.
C. Set Data Lake Storage to use geo-redundant storage (GRS).
D. Deploy identical Azure Stream Analytics jobs to paired regions in Azure.
Guarantee Stream Analytics job reliability during service updates Part of being a fully managed service is the capability to introduce new service functionality and improvements at a rapid pace. As a result, Stream Analytics can have a service update deploy on a weekly (or more frequent) basis. No matter how much testing is done there is still a risk that an existing, running job may break due to the introduction of a bug. If you are running mission critical jobs, these risks need to be avoided. You can reduce this risk by following Azure\’s paired region model.
Scenario: The application development team will create an Azure event hub to receive real-time sales data, including store number, date, time, product ID, customer loyalty number, price, and discount amount, from the point of sale (POS) system and output the data to data storage in Azure
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-job-reliability
Question 3:
You are designing a fact table named FactPurchase in an Azure Synapse Analytics dedicated SQL pool. The table contains purchases from suppliers for a retail store. FactPurchase will contain the following columns.
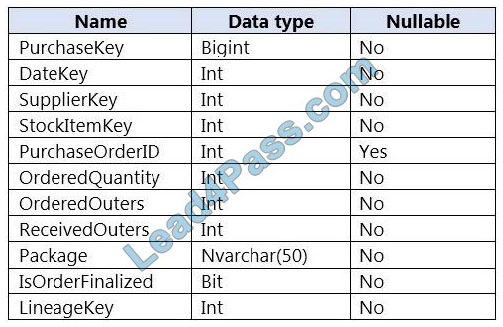
FactPurchase will have 1 million rows of data added daily and will contain three years of data.
Transact-SQL queries similar to the following query will be executed daily.
SELECT SupplierKey, StockItemKey, COUNT(*) FROM FactPurchase WHERE DateKey >= 20210101 AND DateKey <= 20210131 GROUP By SupplierKey, StockItemKey
Which table distribution will minimize query times?
A. replicated
B. hash-distributed on PurchaseKey
C. round-robin
D. hash-distributed on DateKey
Hash-distributed tables improve query performance on large fact tables, and are the focus of this article. Round-robin tables are useful for improving loading speed.
Incorrect:
Not D: Do not use a date column. . All data for the same date lands in the same distribution. If several users are all filtering on the same date, then only 1 of the 60 distributions do all the processing work.
Reference:
Question 4:
You have a table in an Azure Synapse Analytics dedicated SQL pool. The table was created by using the following Transact-SQL statement.

You need to alter the table to meet the following requirements:
Ensure that users can identify the current manager of employees.
Support creating an employee reporting hierarchy for your entire company.
Provide fast lookup of the managers\’ attributes such as name and job title.
Which column should you add to the table?
A. [ManagerEmployeeID] [int] NULL
B. [ManagerEmployeeID] [smallint] NULL
C. [ManagerEmployeeKey] [int] NULL
D. [ManagerName] [varchar](200) NULL
Use the same definition as the EmployeeID column.
Reference: https://docs.microsoft.com/en-us/analysis-services/tabular-models/hierarchies-ssas-tabular
Question 5:
You have files and folders in Azure Data Lake Storage Gen2 for an Azure Synapse workspace as shown in the following exhibit.

You create an external table named ExtTable that has LOCATION=\’/topfolder/\’.
When you query ExtTable by using an Azure Synapse Analytics serverless SQL pool, which files are returned?
A. File2.csv and File3.csv only
B. File1.csv and File4.csv only
C. File1.csv, File2.csv, File3.csv, and File4.csv
D. File1.csv only
To run a T-SQL query over a set of files within a folder or set of folders while treating them as a single entity or rowset, provide a path to a folder or a pattern (using wildcards) over a set of files or folders.
Question 6:
You are designing the folder structure for an Azure Data Lake Storage Gen2 container.
Users will query data by using a variety of services including Azure Databricks and Azure Synapse Analytics serverless SQL pools. The data will be secured by subject area. Most queries will include data from the current year or current
month.
Which folder structure should you recommend to support fast queries and simplified folder security?
A. /{SubjectArea}/{DataSource}/{DD}/{MM}/{YYYY}/{FileData}_{YYYY}_{MM}_{DD}.csv
B. /{DD}/{MM}/{YYYY}/{SubjectArea}/{DataSource}/{FileData}_{YYYY}_{MM}_{DD}.csv
C. /{YYYY}/{MM}/{DD}/{SubjectArea}/{DataSource}/{FileData}_{YYYY}_{MM}_{DD}.csv
D. /{SubjectArea}/{DataSource}/{YYYY}/{MM}/{DD}/{FileData}_{YYYY}_{MM}_{DD}.csv
There\’s an important reason to put the date at the end of the directory structure. If you want to lock down certain regions or subject matters to users/groups, then you can easily do so with the POSIX permissions. Otherwise, if there was a need to restrict a certain security group to viewing just the UK data or certain planes, with the date structure in front a separate permission would be required for numerous directories under every hour directory. Additionally, having the date structure in front would exponentially increase the number of directories as time went on.
Note: In IoT workloads, there can be a great deal of data being landed in the data store that spans across numerous products, devices, organizations, and customers. It\’s important to pre-plan the directory layout for organization, security, and efficient processing of the data for down-stream consumers. A general template to consider might be the following layout:
{Region}/{SubjectMatter(s)}/{yyyy}/{mm}/{dd}/{hh}/
Question 7:
You need to design an Azure Synapse Analytics dedicated SQL pool that meets the following requirements:
Can return an employee record from a given point in time.
Maintains the latest employee information.
Minimizes query complexity.
How should you model the employee data?
A. as a temporal table
B. as a SQL graph table
C. as a degenerate dimension table
D. as a Type 2 slowly changing dimension (SCD) table
A Type 2 SCD supports versioning of dimension members. Often the source system doesn\’t store versions, so the data warehouse load process detects and manages changes in a dimension table. In this case, the dimension table must use a surrogate key to provide a unique reference to a version of the dimension member. It also includes columns that define the date range validity of the version (for example, StartDate and EndDate) and possibly a flag column (for example, IsCurrent) to easily filter by current dimension members.
Question 8:
You have an enterprise-wide Azure Data Lake Storage Gen2 account. The data lake is accessible only through an Azure virtual network named VNET1.
You are building a SQL pool in Azure Synapse that will use data from the data lake.
Your company has a sales team. All the members of the sales team are in an Azure Active Directory group named Sales. POSIX controls are used to assign the Sales group access to the files in the data lake.
You plan to load data to the SQL pool every hour.
You need to ensure that the SQL pool can load the sales data from the data lake.
Which three actions should you perform? Each correct answer presents part of the solution.
NOTE: Each area selection is worth one point.
A. Add the managed identity to the Sales group.
B. Use the managed identity as the credentials for the data load process.
C. Create a shared access signature (SAS).
D. Add your Azure Active Directory (Azure AD) account to the Sales group.
E. Use the snared access signature (SAS) as the credentials for the data load process.
F. Create a managed identity.
The managed identity grants permissions to the dedicated SQL pools in the workspace.
Note: Managed identity for Azure resources is a feature of Azure Active Directory. The feature provides Azure services with an automatically managed identity in Azure AD
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/security/synapse-workspace-managed-identity
Question 9:
You are creating an Azure Data Factory data flow that will ingest data from a CSV file, cast columns to specified types of data, and insert the data into a table in an Azure Synapse Analytic dedicated SQL pool. The CSV file contains three
columns named username, comment, and date.
The data flow already contains the following:
A source transformation.
A Derived Column transformation to set the appropriate types of data.
A sink transformation to land the data in the pool.
You need to ensure that the data flow meets the following requirements:
All valid rows must be written to the destination table.
Truncation errors in the comment column must be avoided proactively.
Any rows containing comment values that will cause truncation errors upon insert must be written to a file in blob storage.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. To the data flow, add a sink transformation to write the rows to a file in blob storage.
B. To the data flow, add a Conditional Split transformation to separate the rows that will cause truncation errors.
C. To the data flow, add a filter transformation to filter out rows that will cause truncation errors.
D. Add a select transformation to select only the rows that will cause truncation errors.
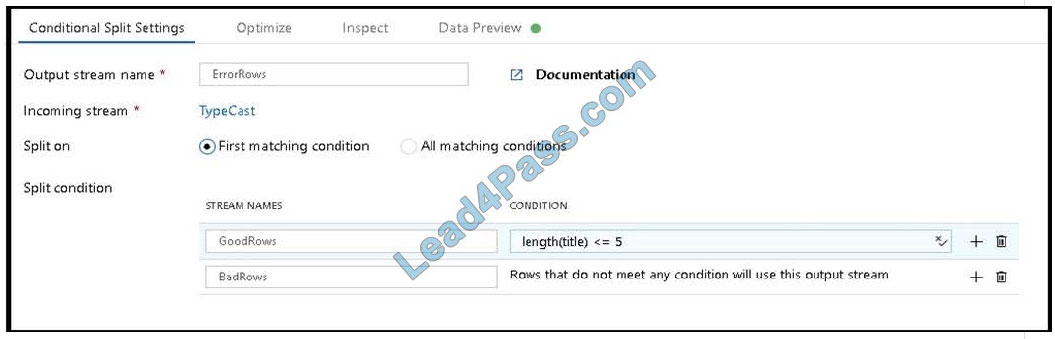
B: Example:
1.
This conditional split transformation defines the maximum length of “title” to be five. Any row that is less than or equal to five will go into the GoodRows stream. Any row that is larger than five will go into the BadRows stream.
2.
This conditional split transformation defines the maximum length of “title” to be five. Any row that is less than or equal to five will go into the GoodRows stream. Any row that is larger than five will go into the BadRows stream.
A:
3.
Now we need to log the rows that failed. Add a sink transformation to the BadRows stream for logging. Here, we\’ll “auto-map” all of the fields so that we have logging of the complete transaction record. This is a text-delimited CSV file output to a single file in Blob Storage. We\’ll call the log file “badrows.csv”.
4.
The completed data flow is shown below. We are now able to split off error rows to avoid the SQL truncation errors and put those entries into a log file. Meanwhile, successful rows can continue to write to our target database.

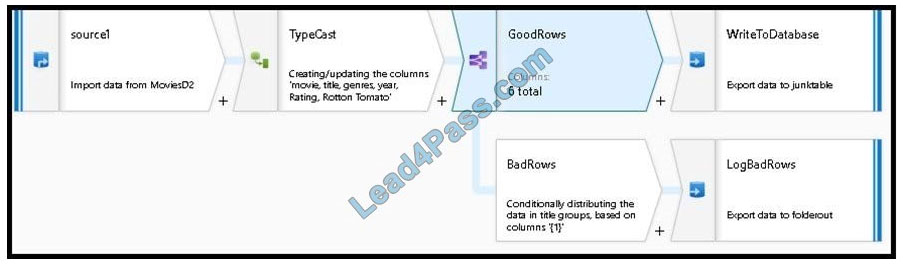
Reference: https://docs.microsoft.com/en-us/azure/data-factory/how-to-data-flow-error-rows
Question 10:
You have an Azure Storage account and a data warehouse in Azure Synapse Analytics in the UK South region.
You need to copy blob data from the storage account to the data warehouse by using Azure Data Factory. The solution must meet the following requirements:
Ensure that the data remains in the UK South region at all times.
Minimize administrative effort.
Which type of integration runtime should you use?
A. Azure integration runtime
B. Azure-SSIS integration runtime
C. Self-hosted integration runtime

Incorrect Answers:
C: Self-hosted integration runtime is to be used On-premises.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/concepts-integration-runtime
Question 11:
You have an Azure Stream Analytics job that receives clickstream data from an Azure event hub.
You need to define a query in the Stream Analytics job. The query must meet the following requirements:
Count the number of clicks within each 10-second window based on the country of a visitor. Ensure that each click is NOT counted more than once.
How should you define the Query?
A. SELECT Country, Avg(*) AS Average FROM ClickStream TIMESTAMP BY CreatedAt GROUP BY Country, SlidingWindow(second, 10)
B. SELECT Country, Count(*) AS Count FROM ClickStream TIMESTAMP BY CreatedAt
GROUP BY Country, TumblingWindow(second, 10)
C. SELECT Country, Avg(*) AS Average FROM ClickStream TIMESTAMP BY CreatedAt GROUP BY Country, HoppingWindow(second, 10, 2)
D. SELECT Country, Count(*) AS Count FROM ClickStream TIMESTAMP BY CreatedAt GROUP BY Country, SessionWindow(second, 5, 10)
Tumbling window functions are used to segment a data stream into distinct time segments and perform a function against them, such as the example below. The key differentiators of a Tumbling window are that they repeat, do not overlap, and an event cannot belong to more than one tumbling window.
Example:
Incorrect Answers:
A: Sliding windows, unlike Tumbling or Hopping windows, output events only for points in time when the content of the window actually changes. In other words, when an event enters or exits the window. Every window has at least one event, like in the case of Hopping windows, events can belong to more than one sliding window.
C: Hopping window functions hop forward in time by a fixed period. It may be easy to think of them as Tumbling windows that can overlap, so events can belong to more than one Hopping window result set. To make a Hopping window the same as a Tumbling window, specify the hop size to be the same as the window size.
D: Session windows group events that arrive at similar times, filtering out periods of time where there is no data.
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-window-functions
Question 12:
You need to schedule an Azure Data Factory pipeline to execute when a new file arrives in an Azure Data Lake Storage Gen2 container.
Which type of trigger should you use?
A. on-demand
B. tumbling window
C. schedule
D. event
Event-driven architecture (EDA) is a common data integration pattern that involves production, detection, consumption, and reaction to events. Data integration scenarios often require Data Factory customers to trigger pipelines based on events happening in storage account, such as the arrival or deletion of a file in Azure Blob Storage account.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/how-to-create-event-trigger
Question 13:
You have two Azure Data Factory instances named ADFdev and ADFprod. ADFdev connects to an Azure DevOps Git repository.
You publish changes from the main branch of the Git repository to ADFdev.
You need to deploy the artifacts from ADFdev to ADFprod.
What should you do first?
A. From ADFdev, modify the Git configuration.
B. From ADFdev, create a linked service.
C. From Azure DevOps, create a release pipeline.
D. From Azure DevOps, update the main branch.
In Azure Data Factory, continuous integration and delivery (CI/CD) means moving Data Factory pipelines from one environment (development, test, production) to another.
Note:
The following is a guide for setting up an Azure Pipelines release that automates the deployment of a data factory to multiple environments.
1.
In Azure DevOps, open the project that\’s configured with your data factory.
2.
On the left side of the page, select Pipelines, and then select Releases.
3.
Select New pipeline, or, if you have existing pipelines, select New and then New release pipeline.
4.
In the Stage name box, enter the name of your environment.
5.
Select Add artifact, and then select the git repository configured with your development data factory. Select the publish branch of the repository for the Default branch. By default, this publish branch is adf_publish.
6.
Select the Empty job template.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/continuous-integration-deployment
Question 14:
You are developing a solution that will stream to Azure Stream Analytics. The solution will have both streaming data and reference data.
Which input type should you use for the reference data?
A. Azure Cosmos DB
B. Azure Blob storage
C. Azure IoT Hub
D. Azure Event Hubs
Stream Analytics supports Azure Blob storage and Azure SQL Database as the storage layer for Reference Data.
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-use-reference-data
Question 15:
You are designing an Azure Stream Analytics job to process incoming events from sensors in retail environments.
You need to process the events to produce a running average of shopper counts during the previous 15 minutes, calculated at five-minute intervals.
Which type of window should you use?
A. snapshot
B. tumbling
C. hopping
D. sliding
Tumbling windows are a series of fixed-sized, non-overlapping and contiguous time intervals. The following diagram illustrates a stream with a series of events and how they are mapped into 10-second tumbling windows.
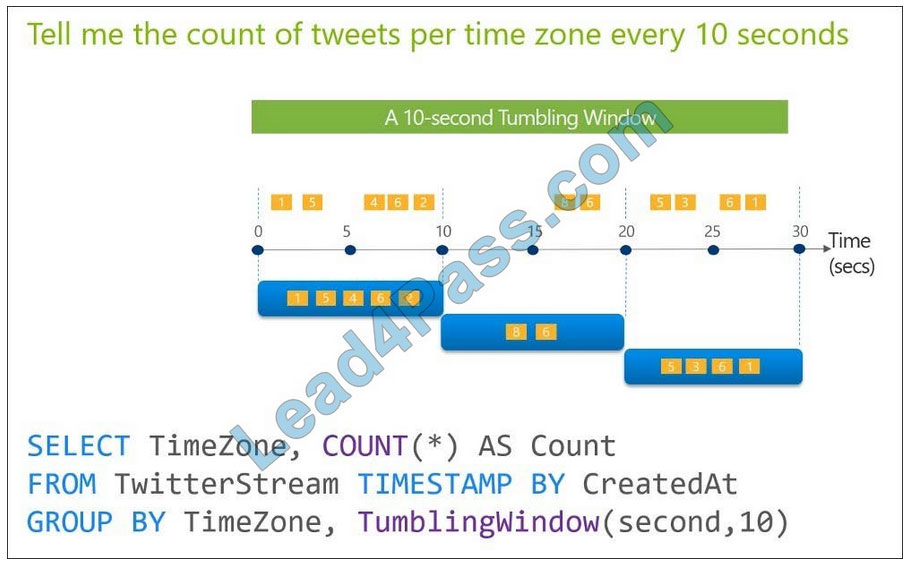
Reference: https://docs.microsoft.com/en-us/stream-analytics-query/tumbling-window-azure-stream-analytics
Publish the answer:
| Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 | Q8 | Q9 | Q10 | Q11 | Q12 | Q13 | Q14 | Q15 |
| D | D | B | A | C | D | D | ADF | AB | A | B | D | C | B | B |
Get more immediate and effective Microsoft DP-203 dumps: https://www.leads4pass.com/dp-203.html (Total Questions: 214 Q&A)
I have shared some historical exam questions above. You can click to view them, and the latest updated Microsoft DP-203 free dumps online exam test. Of course, the most important thing is the advanced exam channel I shared: https://www.leads4pass.com/dp-203.html. leads4pass DP-203 helps you successfully pass the first exam.